Elasticsearch
- 2016.2 ELK 交流. 讲义文稿 GoogleDoc/Slideshare
Tips
- 文档不会被删除,只会被标记删除
- 索引在内存中构建, 然后刷到磁盘
- 一个索引由多个段(segment)组成,搜索会在所有段执行,最终合并结果
- 段会定期合并
- 每个段都会缓存 Field 和 Filter
- Elasticsearch 不支持事务
- 每个分片为一个 Lucene 索引
- 近实时程度与性能有关,默认为 1 秒
- Lucene 自身是增量索引
- 每个段自身为一个小索引
- 1.4 之前默认使用 UUID, 之后使用 Flask ID
- 无法通过查询来删除
- 无法通过查询来更新
- yakaz/elasticsearch-action-updatebyquery 该插件目前已经不可用
- 提议添加该功能 #2230
Best practice
- 只索引不更新
- 日志索引分日期
- 定义好 Mapping
- 挂载多个磁盘使用多个 path.data
- 提升索引速度
- 减少数据丢失
- 如果允许, 增大刷新间隔
- 最大使用 32G 内存, 利用 JVM 压缩指针
- 测试最大内存量
java -Xmx32600m -XX:+PrintFlagsFinal 2> /dev/null | grep UseCompressedOops
bool UseCompressedOops := true
- 1.7 32600m, 1.8 32766m
- 关闭内存 swap
swapoff -a
# 或者
sysctl vm.swappiness=1
# 在 Elasticsearch 配置中添加 bootstrap.mlockall: true
- 如果自定义 ID, 选择一个较好的 ID
- 前缀相同
- 长度相同
- Choosing fast unique id
Reference
- Elasticsearch nightly benchmarks
- Lucene nightly benchmarks
- Articles _ Elasticsearch from the bottom up _ Performance consideration * Performance consideration 2.0
常用操作
批量导入
# 导入前关闭刷新
curl -XPUT localhost:9200/test/_settings -d '{"index" : {"refresh_interval" : "-1"} }'
# 导入前取消副本
curl -XPUT 'localhost:9200/test/_settings' -d '{"index" : {"number_of_replicas" : 0}}'
# 导入完成强制合并
curl -XPOST 'localhost:9200/test/_forcemerge?max_num_segments=5'
更改解析器
# 更改前需要先关闭所有
curl -XPOST 'localhost:9200/test/_close'
curl -XPUT 'localhost:9200/test/_settings' -d '{
"analysis" : {
"analyzer":{
"content":{
"type":"custom",
"tokenizer":"whitespace"
}
}
}
}'
# 完成后打开索引
curl -XPOST 'localhost:9200/test/_open'
诊断
# 查看 jvm 内存状态
curl localhost:9200/_nodes/stats | jq ".nodes[].jvm.mem"
# 单个节点内存状态
curl localhost:9210/_nodes/stats | jq "[.nodes[]]|.[1].jvm.mem"
# 快速信息查看端口, ?help 显示列的含义
curl localhost:9200/_cat
# 查看恢复进度
curl localhost:9200/_cat/recovery
模块
Elasticsearch 的所有功能都是由各个模块组成的.
模块配置分为静态配置和动态配置,静态配置需要在相关节点的 elasticsearch.yml 中指定,动态节点可通过相关接口 进行更改.
| 模块 | 责任 |
|---|---|
| Cluster | 控制如何为节点申请分片. |
| Discovery | 节点在集群中如何相互发现 |
| Gateway | 集群中需要多少节点才能开始恢复 |
| HTTP | 控制 HTTP REST 接口 |
| Indices | 全局索引相关配置 |
| Network | 控制默认网络设置 |
| Node client | 加入到集群中的 Java 客户端,不会持有数据和承担主节点的责任. |
| Plugins | 使用插件来扩展 Elasticsearch |
| Scripting | 定制化的 Lucene Expressions, Groovy, Python, 和 Javascript 脚本. |
| Snapshot/Restore | 备份和恢复数据 |
| Thread pools | Elasticsearch 中的线程池信息 |
| Transport | 传输层控制,节点内部通信 |
| Tribe nodes | A tribe node joins one or more clusters and acts as a federated client across them. |
Query DSL
ES 的所有接口都是通过 RESTful 接口暴露的,因此所有对 ES 的数据操作均可以通过 REST Api 完成.所有的接口也都遵循 HTTP 请求方法语义.
ES 提供了一套通过 JSON 表示的查询接口.查询语句主要包含
- 叶查询语句/Leaf query clauses
- 用于数据的指定字段,例如字段匹配,字段范围等查询.
- 组合查询语句/Compound query clauses
- 使用逻辑运算符来组合一个或多个叶查询或组合查询语句.
查询语句的行为可能会随使用的上下文而发生改变.
查询和过滤上下文
- 查询上下文
- 查询语句在查询上下文中用于回答 "该文档与查询语句有多么匹配" 的问题,在判断一个文档是否匹配的同时,也会计算出每个文档的匹配程度(分数
_score),用于表示该文档与查询的的匹配和相关程度. - 过滤上下文
- 在过滤上下文中查询语句用于回答 "该文档是否匹配该查询语句",其结果只有匹配或不匹配.
GET _search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
查询地址
所有 Elasticsearch 的 API 均以 RESTful 的形式暴露, 基本查询的格式如下
[/索引名[,索引名...]][/类型名[,类型名...]]/_search
查询中的索引名和类型名是可以缺省的,并且也支持通配符,例如如下请求:
curl -XPOST localhost:9200/mq-*/meta,body/_search -d '{"query":{"match_all":{}}}'
Elasticsearch 的查询除了支持 GET 也支持使用 POST, 因为在现有的部分系统里, GET 不允许携带请求体.例如以下请求是相同的:
curl -XGET localhost:9200/_search -d '{"query":{"match_all":{}}}'
curl -XPOST localhost:9200/_search -d '{"query":{"match_all":{}}}'
除此之外, Elasticsearch 也支持针对单个文档的标示符进行查询,例如:
curl -XGET localhost:9200/mq-meta-local/meta/THIS_IS_MY_DOCUMENT_ID
查询类型
Elasticsearch 的底层搜索是 Lucene, 其提供的查询也主要是对 Lucene 查询的封装.
| 查询类型 | 说明 |
|---|---|
| match_all | 匹配所有文档,_score 为 1.0可通过 boost 更改分数值 |
| match | 模糊近似匹配 |
| multi_match | 与 match 相同,可指定多个字段 |
| common_terms | 一个更特殊的查询,会更趋向于选择不常见的词 |
| query_string | 支持 Lucene 查询语法,可使用 AND,OR,NOT 条件,可在单个查询中标示多个字段的搜索需谨慎使用 |
| simple_query_string | 一个更高效的 query_string 版本,适合普通用户使用 |
| term | 匹配字段包含的词 |
| terms | 匹配字段包含的词 |
| range | 使用范围匹配字段的值(日期,数字,字符串等) |
| exists | 匹配非空字段 |
| missing | 匹配不存在字段或为空的字段 |
| prefix | 匹配字段值前缀 |
| wildcard | 使用通配符来匹配字段的值? 单个字符,* 多个字符 |
| regexp | 使用正则表达式来匹配字段的值 |
| fuzzy | 模糊匹配字段的值,使用莱文斯坦距离进行度量. |
| type | 匹配文档类型 |
| ids | 查找文档 ID |
| constant_score | 该查询会包装另外一个查询,并在过滤上下文中执行.所有匹配的文档都会给予一个固定的分数(_score) |
| bool | 用于组合多个 must, should, must_not, 和 filter 查询.must 和 should 语句结果的分数会合并, must_not 和 filter 会在过滤上下文中执行. |
| dis_max | 生成多个子查询的并集,并为单个查询结果中分数最高的文档进行增强. |
| function_score | 使用指定的函数对查询结果的分数进行从新计算. |
| boosting | 可使用指定的查询语句来增强和削弱结果分数. |
| indices | 在指定索引中进行查询 |
| and, or, not | 等同于 bool |
| filtered | 于 2.0.0-beta1 遗弃,使用 bool 查询替代. |
| limit | 限制每个分片查询的文档数 |
| nested | 用于搜索 nested 类型的字段. |
| has_child,has_parent | 用于搜索父子关系的文档. |
| more_like_this | 查询类似于给定的字符串,文档或文档集合. |
| template | 模板查询 |
| script | 脚本查询 |
| geo_shape | 查找形状交叉的文档 |
| geo_bounding_box | 查找点在该矩形内文档 |
| geo_distance | 查找点距之内的文档 |
| geo_distance_range | 查找点距在指定范围内的文档 |
| geo_polygon | 查找点在该多边形内的文档 |
| geohash_cell | 查找点与指定点 geohash 交叉的文档 |
| span_term | 与 term 查询相同,用于与其他跨度查询结合使用 |
| span_multi | 用于包装 term, range, prefix, wildcard, regexp, 或 fuzzy 查询 |
| span_first | 匹配字段满足查询,并且在前 N 位置 |
| span_near | 匹配满足多个查询,并且查询跨度在一定距离内,也可指定是否保持同样的顺序 |
| span_or | 多个跨度查询的逻辑或 |
| span_not | 排除一个跨度查询 |
| span_containing | 指定一列跨度查询,但只返回跨度满足第二个跨度查询的结果 |
| span_within | 指定一个跨度查询,返回跨度满足另外一列跨度查询的结果 |
- 全文查询
- match,multi_match,common_terms,query_string,simple_query_string
- 查询字段必须是 analyzed
- 在查询前会对查询字符串应用字段的解析器(analyzer,search_analyzer)
- 查询字段必须是 analyzed
- 词级查询
- term,terms,range,exists,missing,prefix,wildcard,regexp,fuzzy,type,ids
- 不同于全文查询,在之前需要对查询字符串进行解析.词级查询用于查询字段确切的值.
- 组合查询
- constant_score,bool,filter,dis_max,function_score,boosting,indices,and,or,not,filtered,limit
- 关联查询
- nested,has_child,has_parent
- GEO 查询
- geo_shape,geo_bounding_box,geo_distance,geo_distance_range,geo_polygon,geohash_cell
- 跨度查询
- span_term,span_multi,span_first,span_near,span_or,span_not,span_containing,span_within
- 除了 span_multi 以外,跨度查询不能与非跨度查询混合使用
- https://lucidworks.com/blog/2009/07/18/the-spanquery/
- 除了 span_multi 以外,跨度查询不能与非跨度查询混合使用
Query String
Elasticsearch 可以利用 Lucene 中强大的 query_string 查询语法,其功能强大并且书写简单,也可以直接在 url 中进行查询. 例如:
# Query string syntax
curl -XGET 'localhost:9200/index/type/_search?q=name:wener AND age:>10'
如果将该查询转换为基于 DSL 的查询则是
# DSL syntax
curl -XPOST 'localhost:9200/index/type/_search' -d'
{
"query":{
"bool":{
"must":[
"term":{"name":"wener"},
"range":{"age":{"gt":10}}
]
}
}
}'
可见善用 query_string 查询是非常有用的.在 Kibana 的视图查询界面均是 query_string 查询.
总结
Elasticsearch 对于基础的查询提供了非常多的查询方式,但对于关系型的支持较少,官方建议是在应用端做数据关联,对关系型的处理有一定的复杂度.内置了两种对关系型数据的支持(Nested Object, Parent-Child),但支持都相对较为薄弱,难以处理复杂的场景,还不如使用通常的文档,这样对文档的控制更全面.
参考
高可用机制
Elasticsearch 的高可用是通过分片的多副本保障的.对于每个索引指定一定的分片数量和副本数量.每个文档都有一个唯一标示,通过该标示符来对文档进行分片路由.如果接受到请求的节点没有该分配,则会由该分片转发到该分片主分片的主节点.
ELasticsearch 的高可用形式和 Kafak, Hazelcast 的高可用几乎相同,均是固定分片和副本.
Elasticsearch 集群中节点角色分为主节点,数据节点,客户端节点, Tribe 节点.
所有的索引操作都会对磁盘进行追加操作,而不是直接的对文档进行修改,后台有固定的线程的追加的数据进行合并.
- 同步机制
- 数据刷盘方式
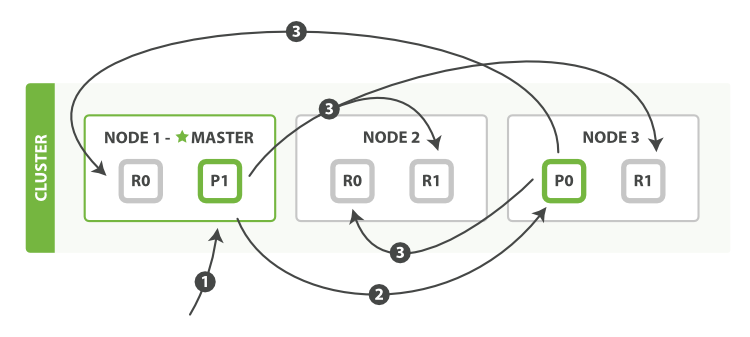
主副本分片交互过程
- 主副本分片结构
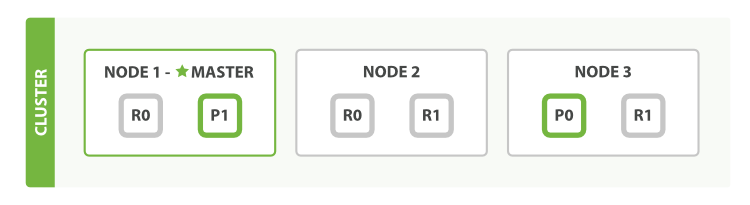
- 创建,索引或删除文档
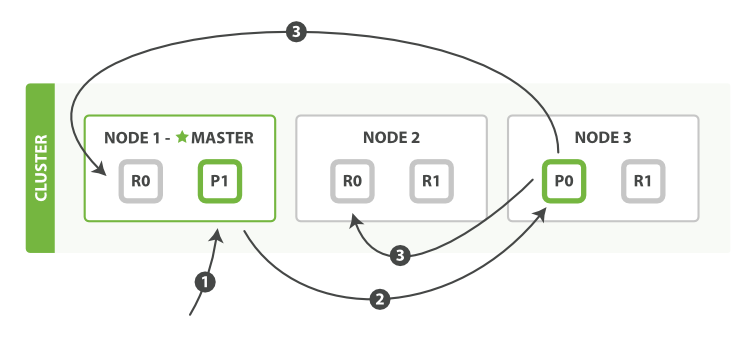
- 获取单个文档
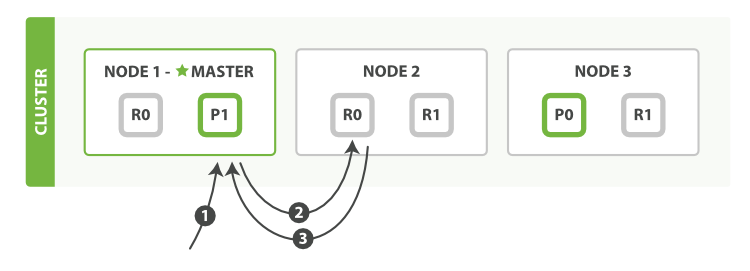
- 部分更新
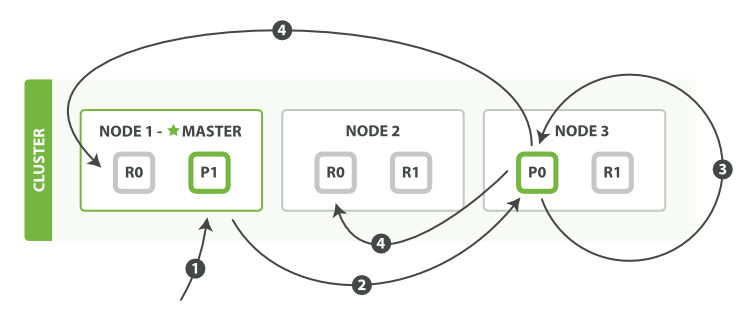
- 即便是部分更新,每次发送给副本的都是一个全量的文档
- 此时的文档分发是异步的,不保证其顺序
- 同时操作多个文档
- mget
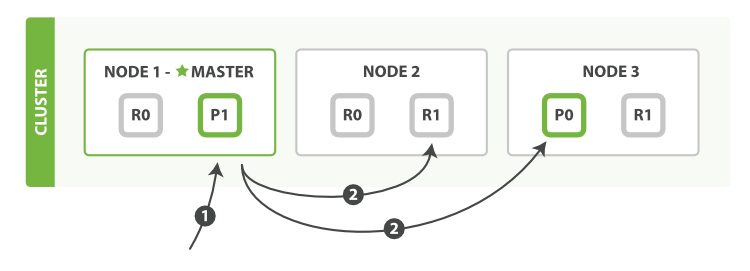
- bulk
- mget
Discovery
- Master
- 唯一可以发布新的集群状态的节点
- 用于响应集群操作,修改节点,增删改索引信息,为节点分配分片
- 索引和搜索等不需要牵涉到主节点
- 用于响应集群操作,修改节点,增删改索引信息,为节点分配分片
discovery.zen:
minimum_master_nodes: 选举主节点的最小 master eligible 节点数,类似于 Zookeeper 里的大多数
ping.unicast: 单播时进行发现的主机信息
master_election:
filter_client: 默认 true
filter_data: 默认 false
fd: Fault Detection
ping_interval : 1
ping_timeout : 30s
ping_retries : 3
publish_timeout : 30s 发布集群状态的超时时间
no_master_block: 当没有 Master 时需要拒绝的操作,不会阻止和节点相关的 API
all
write 默认.可能会读取到过期数据.
Local Gateway
- 用于本地存储集群节点和分片信息.即便在集群完全重启后也会保持.
- 存储的节点和集群信息会用于确定何时进行数据恢复调度.
- 配置项的更改只有在集群完全重启后才会生效.
参考
恢复备份
Elasticsearch 支持快照和恢复
# 需要配置 path.repo: /home/data/es-backup
# Snapshot repository
curl -XPUT 'localhost:9200/_snapshot/backup' -d '{
"type": "fs",
"settings": {
"compress": "true",
"location": "/home/data/es-backup/backup"
}
}'
curl -XGET localhost:9200/_snapshot/backup?pretty
curl -XGET localhost:9200/_snapshot/_all?pretty
# Backup
curl -XPUT 'localhost:9200/_snapshot/backup/bckp1'
curl -XPUT 'localhost:9200/_snapshot/backup/bckp2?wait_for_completion=true&pretty'
curl -XPUT 'localhost:9200/_snapshot/backup/bckp?wait_for_completion=true&pretty' -d '{
"indices": "mq-*",
"ignore_unavailable": "true",
"include_global_state": false,
"partial":false
}'
# Restore
curl -XPOST 'localhost:9200/_snapshot/backup/bckp1/_restore'
curl -XPOST 'localhost:9200/_snapshot/backup/bck1/_restore?pretty' -d '{"indices": "c*"}'
# Cancel/Delete
curl -XDELETE 'localhost:9200/_snapshot/backup/bckp1/_restore'
参考
数据建模
Parent-Child
- Parent Child Relationship
- 适合于子文档特别多,父文档较少的情况
- 父子关系的映射会存储在内存中
- 更新父文档不影响子文档
- 增删改子文档不影响父文档
- 减少父文档 ID 长度
- 父子都存储在同一个分片
- 可以实现祖孙关系,增加时需要使用 routing 来指定分片
- has_child filter 不会缓存
- 搜索子文档时,避免使用 score_mode
GET /_nodes/stats/indices/id_cache?human可查看用于缓存父子占用的内存- 每次索引更改需要重建 Global Ordinals,当父文档较多时,需要占用大量的时间,可通过修改 fielddata 的 loading 来使其发生在 refresh 时而不是 query 时.
Nested Object
聚合
内存控制
- Controlling Memory
- $ES_HEAP_SIZE 可用于控制堆大小,小于可用的一半,小于 32G
Fielddata
- 会将所有文档的 fielddata 加载到内存,主要是 uinvert index
- 缓存以段位单位
- 主要用于排序,聚合和部分过滤及脚本
插件
常用插件
- mobz/elasticsearch-head A web front end for an elastic search cluster
- lmenezes/elasticsearch-kopf web admin interface for elasticsearch
- royrusso/elasticsearch-HQ/online Monitoring and Management Web Application for ElasticSearch instances and clusters.
- delete-by-query
- Update by query
- yakaz/elasticsearch-action-updatebyquery 该插件目前已经不可用
- #2230 添加 Update by query 请求,目前已经合并还未发布
- bigdesk
插件开发
更新
更新主要指部分更新,部分更新在复杂场景下是非常常见的常见.部分更新分为脚本和文档合并两种方式.
curl -XPUT "localhost:9200/test/test/1" -d '{"name":"wener","age":15}'
# 需要
# script.inline: true
curl -XPOST "localhost:9200/test/test/1/_update" -d '{"script" : "ctx._source.age=16"}'
curl -XPOST "localhost:9200/test/test/1/_update" -d '{"script" : "ctx._source.sex='男'"}'
# params for script
curl -XPOST "localhost:9200/test/test/1/_update" -d '{
"script" : "ctx._source.age=age",
"params" : {
"age" : 20
}
}'
# upsert for missing
curl -XPOST "localhost:9200/test/test/1/_update" -d '{
"script" : "ctx._source.score+=1",
"upsert": {
"score": 0
}
}'
# doc for partial update
curl -XPOST "localhost:9200/test/test/1/_update" -d '{
"doc":{
"friends":[
"XXX"
]
}
}'
# doc_as_upsert will insert this doc if missing
curl -XPOST "localhost:9200/test/test/2/_update" -d '{
"doc":{
"friends":[
"CCC"
]
},
"doc_as_upsert": true
}'
# remove field
curl -XPOST "localhost:9200/test/test/1/_update" -d '{
"script" : "ctx._source.remove('friends')"
}'
翻页
默认翻页内容最多 10000 条(配置项 index.max_result_window),
vs Others
将 Elasticsearch 和其他产品做比较时,需要先考虑它的设计初衷
- 一次写多次读
- 符合日志的特性
- 能够做大量缓存
- 搜索
- 统计分析
Elasticsearch 自身本可以作为主数据库使用, 但目前常用的做法都是作为一个附属库,当数据被写入到一个支持事务的高一致性的存储(HBase,PostgreSQL)后,再异步推送到 Elasticsearch 进行索引,以实现对存储的数据进行高性能的检索和分析.
MongoDB
MongoDB 是用于传统用途(CRUD) 的基于文档的数据库,其主要特色不是搜索或者统计分析,而是能够以数据本身的文档结构进行存储.
MongoDB 与 Elasticsearch 两者并不违背,可以同时使用.
虽然 Elasticsearch 不需要 Schema ,但是因为底层为 Lucene, 所有的文档都会扁平化处理,因此无法真正的把 Elasticsearch 作为 Schemaless 来使用,反而需要慎重的对待.而 MongoDB 却能很好地做到 Schemaless, 可以从 JavaScript 的处理角度出发看待起处理文档的方式.
Elasticsearch 大多情况适用于处理小文档,当处理不需要索引的大文档时,其功能有限.而 MongoDB 支持 GridFS, 可以很好地使用同一套接口来处理大文档.
Solar
FAQ
指定配置文件
启动时可通过 path.conf 来指定配置文件目录, 读取的配置文件来该目录下的 elasticsearch.yml, 不能直接指定该配置文件,也不能修改该配置文件名.
# 确保目录下配置文件正确
ls my-config
elasticsearch.yml logging.yml
# 启动时指定配置目录
./bin/elasticsearch -Dpath.conf=my-config
使用 ROOT 启动
Elasticsearch 默认是不允许使用 ROOT 用户启动的,可通过启动时添加 es.insecure.allow.root 参数允许使用 ROOT 启动.
# 允许使用 ROOT 启动
./bin/elasticsearch -Des.insecure.allow.root=true
Java 版本
Elasticsearch 对 Java 版本有要求,至少需要 1.7, 并且在 1.7 的某些版本中的 Bug 可能会影响 Lucene 的一致性,因此 Elasticsearch 在启动时会给予警告.
Exception in thread "main" java.lang.RuntimeException: Java version: Oracle Corporation 1.7.0_45 [Java HotSpot(TM) 64-Bit Server VM 24.45-b08] suffers from critical bug https://bugs.openjdk.java.net/browse/JDK-8024830 which can cause data corruption.
Please upgrade the JVM, see http://www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html for current recommendations.
If you absolutely cannot upgrade, please add -XX:-UseSuperWord to the JAVA_OPTS environment variable.
Upgrading is preferred, this workaround will result in degraded performance.
at org.elasticsearch.bootstrap.JVMCheck.check(JVMCheck.java:123)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:283)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
Refer to the log for complete error details.
Use -XX:-UseSuperWord if you are running on 7u40 <= JVM < 7u55
使用 term 查找不到指定内容
-
当使用 term 进行全文匹配时,要求查找的字段为非解析字段,否则无法进行全文匹配.
-
大写会存储为小写,查询时需要手动转为小写.