Reflex Based Models
- Reflex agent
- 从环境中获取输入
- 通过预测器,预测输出
- 输出结果
非线性
- Quadratic predictors
- 二次预测器
- Quadratic clasifiers
- 二次分类器
- Decision boundary - 一个圆
- Piecewise constant predictors
- 分段常数预测器
- Predictors with periodicity structure
- 周期性结构预测器
Linear predictors
- feature template
- 特征模板
- group of features all computed in a similar way
- e.g. 字符串 以 .com,.cn 结尾
- group of features all computed in a similar way
- dense feature
- sparse feature
- 大量 0
Linear classifier
Margin
- larger values are better
Linear regression
Residual
amount by which the prediction overshoots the target
Loss minimization
- Loss function
- 损失函数
- weights , output , input .
- Classification case
- 分类问题
| Name | Zero-one loss | Hinge loss | Logistic loss |
|---|---|---|---|
| Loss | |||
| Illustration |  |  |  |
Regression case
| Name | Squared loss | Absolute deviation loss |
|---|---|---|
| Illustration |  |  |
Zero-one loss
Logistic regression
Loss minimization framework
- group DRO
- Group distributionally robust optimization
Non-linear predictors
- -nearest neighbors
- KNN
- 相邻
- 用于分类、回归
- 相邻
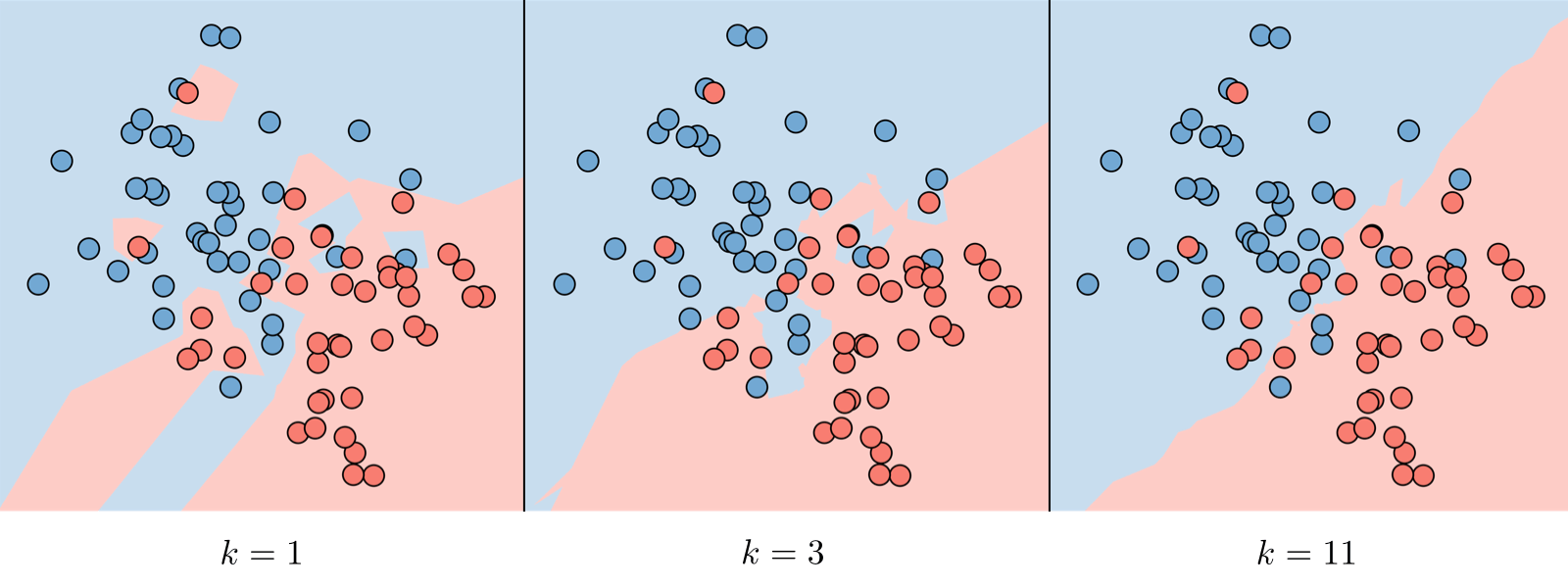
-
- 与 bias 成正比
- 与 variance 成反比
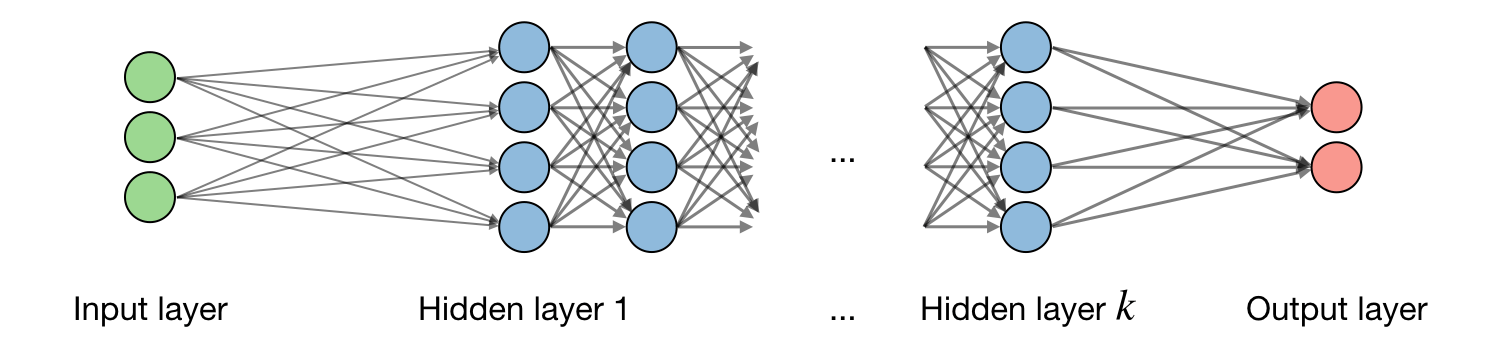
- Neural networks
- 神经网络
- w - weight
- b - bias
- x - input
- z - non-activated output
Stochastic gradient descent
- Gradient descent
- 梯度下降
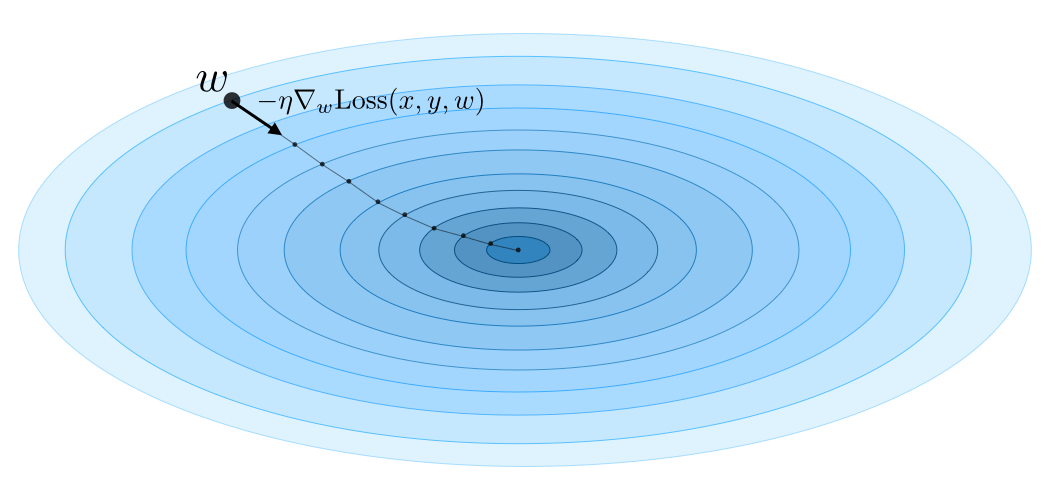
-
- learning rate - step size
- 学习速率 - 每次更新多少
- Stochastic gradient descent - SGD
- 随机梯度下降
- Stochastic updates - 每次训练更新
- Batch gradient descent - BGD
- 批量梯度下降
- Batch updates - 一次训练集更新一次
Fine-tuning models
- Hypothesis class
- 假设类
- Logistic function
- 逻辑函数
- - sigmoid function
- Backpropagation
- 后向传播
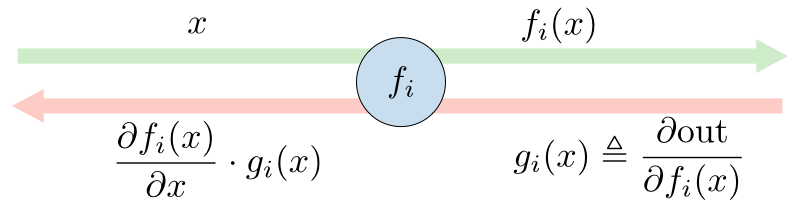
- Approximation error
- hypothesis <-> predictor
- Estimation error
- predictor <-> best predictor
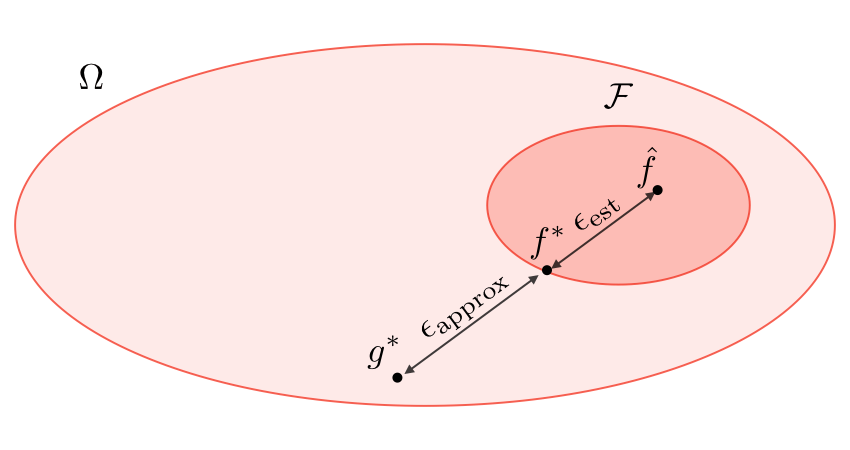
- Regularization
- keep the model from overfitting
- LASSO
- Shrinks coefficients to 0
- Good for variable selection
- Ridge
- Makes coefficients smaller
- Elastic Net
- Tradeoff between variable selection and small coefficients
- Hyperparameters
- Sets vocabulary
| Training set | Validation set | Testing set |
|---|---|---|
| 训练集 | 验证集 hold-out development set | 测试集 |
| 80% | 20% | |
| 用于训练模型 | 用于估算模型 | 模型未见过的数据 |
Unsupervised Learning
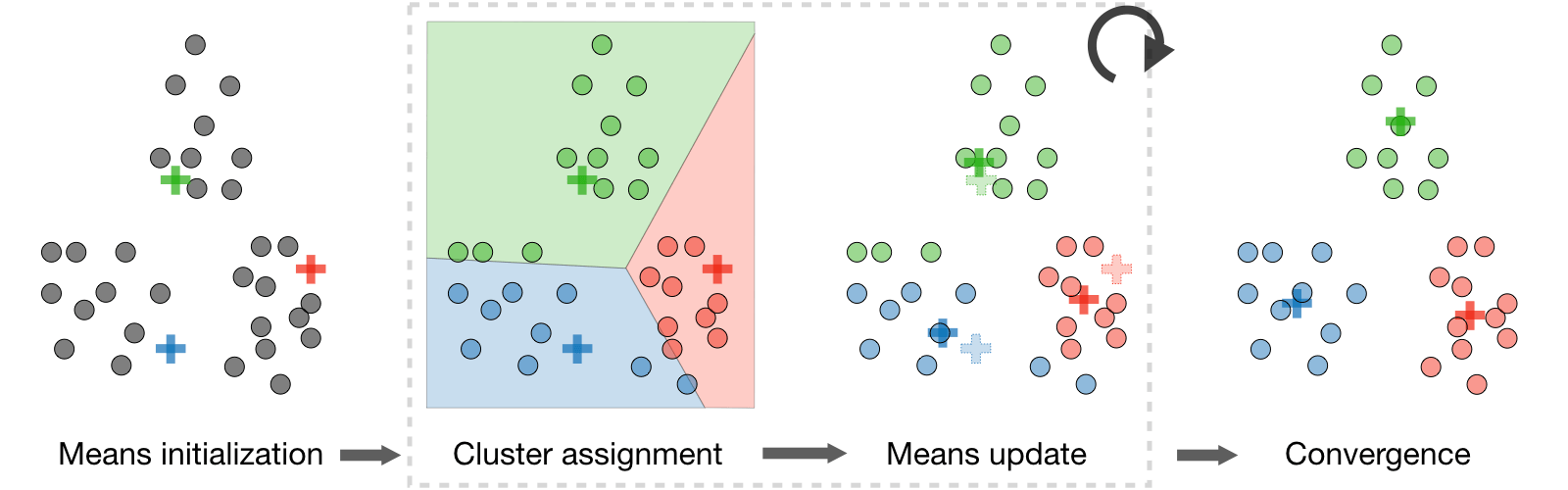
k-means
- Clustering
- , clustering 将点 划分为 类
- Objective function
- 初始化 clustering 的函数
- 选取 个点作为初始的 个 cluster 的中心点
- 选取 个点作为初始的 个 cluster 的中心点
- k-means
- 随机选取 个点作为初始的 个 cluster 的中心点 - Objective function 2. 计算每个点到 个 cluster 的中心点的距离 - Algorithm 3. 将每个点划分到距离最近的 cluster 4. 重新计算每个 cluster 的中心点 5. 重复 2-4 直到收敛
Algorithm
Principal Component Analysis
- Eigenvalue, eigenvector
Spectral theorem
Misc
-
- is the output
- is the input
- is the weight
- is the bias
- 有监督学习
- 有输入和输出
- 输入是特征
- 输出是标签
- 通过学习输入和输出的关系, 从而预测未知的输出