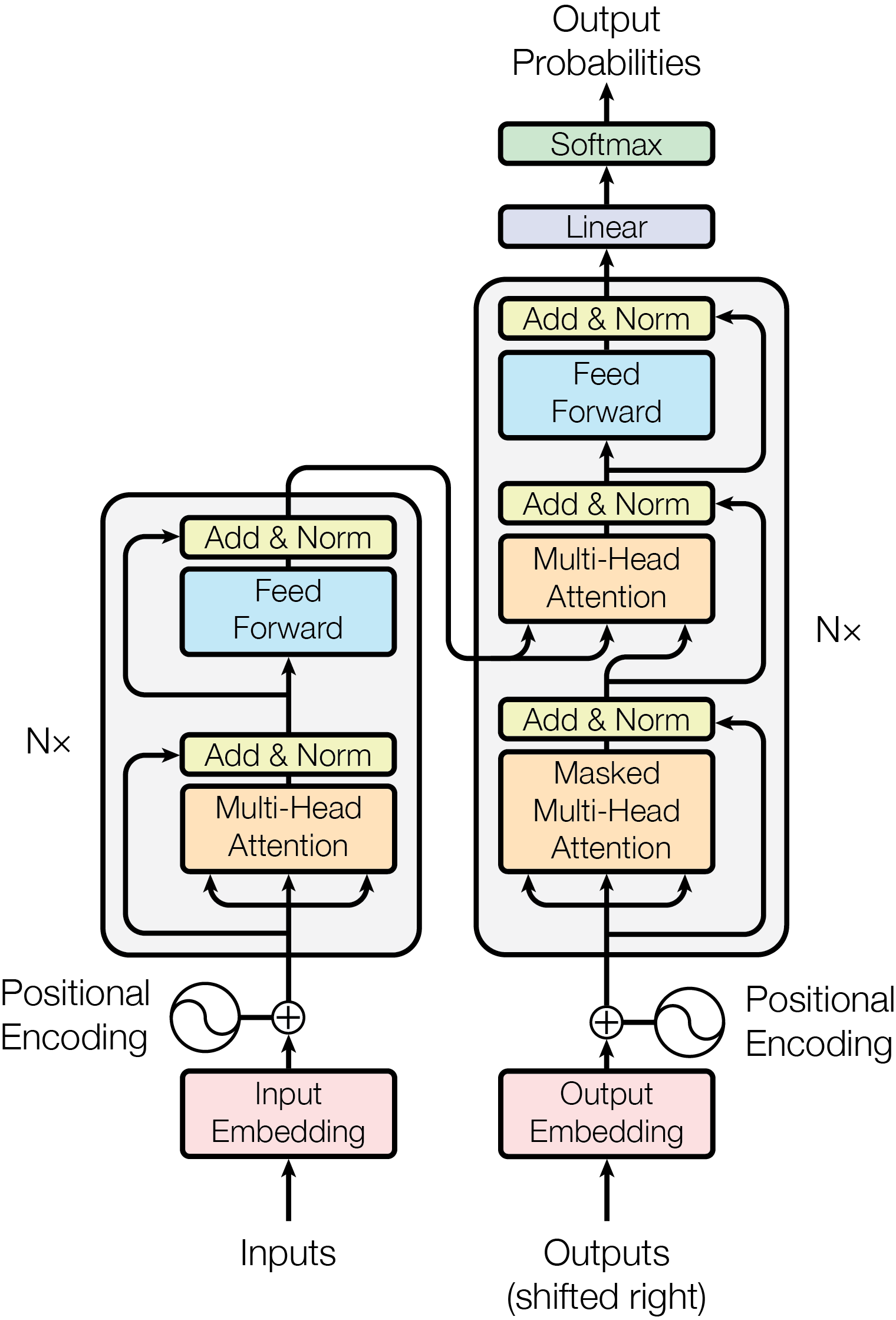
Transformer
- GPT Model
- 组成
- Token Embedding(Vocab Size, Embedding Dimension)
- Positional Embedding(Context Length, Embedding Dimension)
- N × Transformer Block
- Transformer Block
- Layer Norm(Embedding Dimension)
- Normalization Activation
- OutputHead = Linear(Embedding Dimension, Vocab Size)
- 计算流程
- Tokenization - Tokenizer(input) -> Token IDs
- Text -> Token IDs
- BPE
- CPU Bound
- Embeding Lookup -> Input Embeddings
- (vocab_size, hidden_dim)
- Embedding Matrix
- Positional Embedding(Sequence Length) -> Positional Embeddings
- Input Embeddings = Token Embeddings + Positional Embeddings
- Input Embeddings = Dropout(Input Embeddings)
- Outputs = N × Transformer Block(Input Embeddings)
- Outputs = Layer Norm(Outputs)
- Logits = OutputHead(Outputs)
- Tokenization - Tokenizer(input) -> Token IDs
- 采样 Logits 得到下一个 Token,将其添加到输入序列中,重复上述过程直到生成结束
- 组成
- Transformer Block = Attention + Feed Forward Network + Layer Norm + Residual
- 模型层数为 Block 数量
- Tokenization - Embedding - Positional encoding - Transformer block - Attention
- Context QKV
- Attention Pattern
- Self Attention
- Cross Attention
- KV 不同 dataset
- Multi-head Attention
- Single Head Attention
- Sparse Attention Mechanism
- Blockwise Attention
- Linformer
- Reformer
- Ring Attention
- GQA - Grouped Query Attention
- SwiGUL
- RMSNorm
- YARN(Yet Another RoPE extensioN)
- DCA - Dual Chunk Attention - 双块注意力
- 参考
tip
- parameters 表示可训练的参数数量
| abbr. | stand for | meaning | notes |
|---|---|---|---|
| BOS | Beginning Of Sequence | ||
| EOS | End Of Sequence | <|endoftext|> | |
| PAD | Padding | 填充 |
attn_scores = torch.empty(6, 6)
# 矩阵乘法
# for i, x_i in enumerate(inputs):
# for j, x_j in enumerate(inputs):
# attn_scores[i, j] = torch.dot(x_i, x_j)
# 等同于
attn_scores = inputs @ inputs.T
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_context_vecs = attn_weights @ inputs
伪代码
- Prefill 阶段
- 计算密集
- Predict next token 阶段
- 内存密集
# KV 缓存, 模型的每一层都有自己的 K 缓存和 V 缓存
# 它的形状大致是: [层数, 2 (K/V), 批次大小, 头数, 序列长度, 每个头的维度]
KV_CACHE = initialize_empty_cache()
LLM_MODEL = load_model()
# 阶段一:Prefill
def prefill(prompt_tokens):
# 输入: 一个 token 序列, 例如 [T1, T2, ..., TN],长度为 N
# 1. 并行计算:一次性通过模型处理所有 N 个 token。
# 在这个过程中,对于每一层,每个 token Ti 都会与它自己和它之前的所有 token (T1...Ti)
# 进行自注意力计算,并生成自己的 K 和 V 向量。
# all_hidden_states 的形状是 [N, hidden_dim]
all_hidden_states, all_k_vectors, all_v_vectors = LLM_MODEL.forward(prompt_tokens)
# 2. 填充 KV 缓存 (关键步骤)
# 将一次性计算出的、属于这 N 个 token 的所有 K, V 向量,整体存入全局缓存
KV_CACHE.fill_with(all_k_vectors, all_v_vectors)
# 3. 预测第一个新词
# 只用最后一个 token (TN) 的最终输出状态来预测下一个词
last_token_state = all_hidden_states.last()
next_token_logits = calculate_logits(last_token_state)
first_new_token = sample(next_token_logits) # 例如生成了 T(N+1)
return first_new_token
# 阶段二:解码 (循环调用,直到生成结束)
def decode_one_token(new_token):
# 输入: 上一步刚生成的单个 token, 例如 T(N+1)
# 1. 增量计算:只通过模型处理这一个新 token。
# 关键点:在 forward pass 内部,模型会接收完整的 KV_CACHE 作为历史信息。
# hidden_state 的形状是 [1, hidden_dim]
hidden_state, new_k, new_v = LLM_MODEL.forward(new_token, past_kv_cache=KV_CACHE)
# --- 在 forward pass 内部的自注意力计算细节 ---
# a. 为 new_token (T(N+1)) 计算出它的 Query 向量: Q(N+1)
# b. 从 KV_CACHE 中快速读取出之前所有 token 的 Key 向量: [K1, K2, ..., KN]
# c. 计算 Attention Scores:
# 对于 T(N+1) 来说,它需要和包括它自己在内的所有历史 token 计算相关性。
# score_i = dot_product(Q(N+1), Ki) (其中 i 从 1 到 N+1)
# 这里的 K1..KN 直接从缓存读取,极大节省了计算!
# d. 计算 Attention Weights (Softmax), 然后根据权重对 V1..V(N+1) 进行加权求和...
# --------------------------------------------------
# 2. 更新 KV 缓存
# 只把这个新 token 的 K, V 向量追加到缓存的末尾
KV_CACHE.append(new_k, new_v)
# 3. 预测下一个词
next_token_logits = calculate_logits(hidden_state)
next_token = sample(next_token_logits) # 例如生成了 T(N+2)
return next_token
# --- 整体流程 ---
prompt = "在一个漆黑的暴风雨之夜"
prompt_tokens = tokenize(prompt)
# 执行 Prefill,生成第一个词
next_token = prefill(prompt_tokens)
generated_sequence = [next_token]
# 循环执行 Decode,生成后续的词
while next_token is not "[END_OF_SEQUENCE]":
next_token = decode_one_token(next_token)
generated_sequence.append(next_token)
- Input Text
- Tokenize Text
- Token IDs
- Input Embeddings = Token Embeddings + Positional Embeddings
- Transformer Blocks
- Multi-Head Self-Attention
- Feed-Forward Network
- Post-processing
- Layer Normalization
- Linear Layer
- Softmax
- Output Probabilities
- Sample Next Token
- Repeat from Step 3 until EOS or max length
- Output Text
架构参数
- parameters
- 模型参数数量
- data type / quantization
- 数据类型 / 量化
- attention
- 注意力类型
- GQA
- vocab size / vocabulary size / 词汇表大小
- 过小的词汇表会再多语言场景导致性能问题
- context length
- 上下文长度
- embedding dimension / d_model / residual stream dimension / Hidden Size
- 嵌入维度、模型维度
- 一个 token 的表示向量维度
- Number of QKV Heads
- 注意力头数
- GQA 例如 80/8/8
- Head Size - 每个注意力头的维度
- layers / hidden layers
- Transformer 层数 / transformer blocks
- dropout rate
- Dropout 率
- 避免 overfitting
- learning rate
- 学习率
- qkv bias
- QKV 偏置
- 是否在计算 Q、K、V 的线性层中包含偏置向量
- dense or MoE
- dense 全激活
- MoE 部分激活 - 可能质量会差,但计算效率更高
- activation function - 激活函数
- MoE 时候的 门控机制
- SwiGLU
- Active Experts / 活跃专家数
- Expert Size / 专家大小
- RoPE Base Frequency
- RoPE 基础频率
- 影响模型对长序列的处理能力
- 例如 1e7
- 语言数量
- 语料大小
Papers
- Attention Is All You Need
- 2017-06, Google
- 核心贡献: 提出了完全基于 Self-Attention 的 Transformer 架构,彻底取代了RNN,开启了现代大模型的时代。
- Improving Language Understanding by Generative Pre-Training
- 2018-06, OpenAI
- 核心贡献: 提出 GPT-1,开创了 Decoder-Only 架构以及“生成式预训练 + 任务微调”的强大范式。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 2018-10, Google
- 核心贡献: 提出 BERT 模型,利用 Encoder-Only 架构和掩码语言模型(Masked LM)实现了真正的双向上下文理解,统治了自然语言理解(NLU)任务数年。
- Language Models are Unsupervised Multitask Learners
- 2019-02, OpenAI
- 核心贡献: 提出 GPT-2,证明了通过扩大模型规模和数据量,模型无需微调就能展现出惊人的零样本(Zero-Shot)多任务处理能力。
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- 2019-09, NVIDIA
- 核心贡献: 提出了一套行之有效的模型并行技术,解决了单GPU无法容纳超大模型的问题,为训练百亿、千亿参数模型铺平了道路。
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- 2019-10, Google
- 核心贡献: 提出 T5 模型,将所有NLP任务统一为“文本到文本(Text-to-Text)”格式,展现了惊人的通用性。
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- 2019-10, Microsoft
- 核心贡献: 提出 ZeRO 显存优化技术,通过在多个GPU间切分和管理模型状态,极大地降低了训练超大模型的硬件门槛。
- Scaling Laws for Neural Language Models
- 2020-01, OpenAI
- 核心贡献: 首次系统性地揭示了模型性能与模型大小、数据量、计算量之间的可预测的幂律关系(Scaling Law),指导了后续的大模型军备竞赛。
- Language Models are Few-Shot Learners
- 2020-05, OpenAI
- 核心贡献: 提出 GPT-3,展示了巨大模型规模下惊人的**上下文学习(In-Context Learning)和少样本(Few-Shot)**能力,用户无需微调,仅通过提供几个示例就能让模型完成任务。
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 2021-01, Google
- 核心贡献: 提出了专家混合网络 (Mixture-of-Experts, MoE) 架构,通过每次只激活一部分“专家”网络,实现了在保持计算成本基本不变的情况下,将模型总参数量扩展到万亿级别。
- Evaluating Large Language Models Trained on Code
- 2021-08, OpenAI
- 核心贡献: 推出 Codex 模型,证明了在大量代码数据上训练的大模型,具备强大的代码生成和理解能力,是 GitHub Copilot 的技术基础。
- On the Opportunities and Risks of Foundation Models
- 2021-08, Stanford
- 核心贡献: 提出了“基础模型 (Foundation Models)”这一术语和概念,深刻地定义了新一代AI模型的范式。
- Finetuned Language Models are Zero-Shot Learners
- 2021-09, Google
- 核心贡献: 提出 FLAN,证明了通过指令微调 (Instruction Finetuning),可以极大地激发模型在未知任务上的零样本泛化能力。
- Improving language models by retrieving from trillions of tokens
- 2021-12, DeepMind
- 核心贡献: 提出 RETRO 模型,是检索增强生成 (RAG) 领域的早期重要探索,通过让模型从一个巨大的数据库中检索相关信息来辅助生成,以提升事实准确性。
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- 2022-01, Google
- 核心贡献: 提出了思维链 (Chain-of-Thought, CoT) 提示技术,通过引导模型“一步一步地思考”,显著提升了其在数学和逻辑推理任务上的表现。
- Training language models to follow instructions with human feedback
- 2022-03, OpenAI
- 核心贡献: 提出 InstructGPT,系统性地阐述了通过基于人类反馈的强化学习 (RLHF) 来进行模型对齐 (Alignment) 的三步法,是 ChatGPT 的直接技术前身。
- Training Compute-Optimal Large Language Models
- 2022-04, DeepMind
- 核心贡献: 提出 Chinchilla 模型和计算最优缩放定律,指出过去的大模型训练时“模型太大而数据太少”,要达到最优性能,数据量和模型参数量应该按比例同步增长。
- Emergent Abilities of Large Language Models
- 2022-06, Google
- 核心贡献: 提出了大模型的“涌现能力 (Emergent Abilities)”概念,即很多复杂能力(如多步推理)只在模型规模达到某个阈值后才会突然出现。
- LLaMA: Open and Efficient Foundation Language Models
- 2023-02, Meta
- 核心贡献: 推出 LLaMA 系列,证明了用更小、但更高质量的数据集训练,也能达到顶尖性能。其开源版本极大地推动了整个开源LLM生态的发展。
- GPT-4 Technical Report
- 2023-03, OpenAI
- 核心贡献: 推出 GPT-4,展现了在多模态理解、推理和遵循复杂指令方面的顶级性能,设立了新的行业标杆。
- Visual Instruction Tuning
- 2023-04, UW–Madison & Microsoft
- 核心贡献: 提出 LLaVA,开创了通过指令微调来高效构建多模态视觉语言模型的简洁范式,引爆了开源VLM生态。
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- 2023-05, Stanford
- 核心贡献: 提出 DPO 算法,作为 RLHF 的一种更简单、更稳定的替代方案,用于模型对齐。
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- 2023-05, Google & Princeton
- 核心贡献: 提出 思维树 (Tree of Thoughts, ToT),一种比CoT更高级的提示框架,允许模型对一个问题探索多个不同的推理路径,并进行评估和选择。
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- 2023-07, Meta
- 核心贡献: 推出 LLaMA 2,是第一个被广泛允许免费商业使用的、性能顶尖的开源大模型系列。
- Mistral 7B
- 2023-10, Mistral
- 核心贡献: 证明了**小尺寸模型(7B)**通过优秀的架构设计(如滑动窗口注意力、分组查询注意力)也能达到远超其规模的性能,引领了“小而精”的模型设计潮流。
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 2023-12, CMU & Princeton
- 核心贡献: 提出 Mamba,一种基于状态空间模型 (SSM) 的新架构,在处理长序列时具有线性时间复杂度和恒定的推理成本,成为 Transformer 架构的有力挑战者。
- The Llama 3 Herd of Models
- 2024-05, Meta
- 核心贡献: 推出 Llama 3 系列,通过在超大规模(15T+ tokens)、高质量的数据上进行预训练,将开源模型的性能推向了新的高度。
- The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
- 2024-06, HuggingFace
- 核心贡献: 发布了 FineWeb,一个规模巨大(15万亿 token)、经过极致过滤和去重的高质量开源网络数据集,旨在为社区提供比通用网络爬取(如 Common Crawl)更优质的LLM预训练“食粮”。
- OLMoE: Open Mixture-of-Experts Language Models
- 2024-09, AI2
- 核心贡献: 发布了 OLMoE,一个完全开源的专家混合(MoE)模型系列。不仅开放权重,更开放了完整的训练数据、代码和日志,并引入了“Truss Router”等技术提升MoE效率,极大地推动了MoE模型的透明度和可复现性。
- Qwen2.5 Technical Report
- 2024-12, Alibaba
- 核心贡献: 发布了通义千问 Qwen2.5 系列模型,包括一个性能强大的 350B 密集模型和一个 90B 的 MoE 模型。其主要进步在于超长上下文(支持256K)下的推理能力和强大的智能体(Agent)工具调用能力,并在多个基准上达到了SOTA性能。
- DeepSeek-V3 Technical Report
- 2024-12, DeepSeek
- 核心贡献: 发布了 DeepSeek-V3,一个在代码和数学推理方面表现极其出色的 MoE 模型。它通过在海量高质量代码和数学数据上进行训练,旨在成为开发者和科研人员最强大的开源编程与推理助手。
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 2025-01, DeepSeek
- 核心贡献: 提出了 DeepSeek-R1,这是一种创新的强化学习对齐方法。与传统RLHF/DPO只关注最终答案不同,该方法通过奖励正确的“思考过程”(Chain-of-Thought),来专门激励和增强模型的逻辑推理能力,使其“不仅知其然,更知其所以然”。
Attention Is All You Need
- 2017-06, Google
- 引入 Transformer 模型架构,改变了自然语言处理领域
- 打破了顺序处理的枷锁,实现了大规模并行计算。
- 极大地提升了模型捕捉“长距离依赖”的能力。
- RNN/LSTM 的时代与困境
- 计算效率低下 (无法并行) - 海量训练数据不现实
- 长距离依赖问题 (信息丢失)
- 用自注意力机制 (Self-Attention) 实现并行计算
- 用自注意力机制解决长距离依赖
- 深远实际意义
- 奠定了现代大语言模型 (LLM) 的基础
- 开启了“预训练+微调”的新范式
- 推动了模型规模的“军备竞赛”
- 跨领域的范式转移
- Attention Is All You Need
- https://yiyibooks.cn/arxiv/1706.03762v7/index.html
- Dive in
- https://nlp.seas.harvard.edu/annotated-transformer/
- https://jalammar.github.io/illustrated-transformer/
- Attention in transformers, step-by-step | Deep Learning Chapter 6 https://www.youtube.com/watch?v=eMlx5fFNoYc
- Decoder Only
- GPT-1, GPT-2, GPT-3
- Masking
- Self Attention
- 自回归语言模型 (Autoregressive LM) 逐字预测下一个词
- Encoder Only
- BERT, RoBERTa, ALBERT
- 掩码语言模型 (Masked LM) 掩码预测被遮盖的词
- Encoder-Decoder
- T5, BART
- Cross Attention
- 序列到序列 (Seq2Seq) 模型,适用于翻译等任务
- Next
- 生成 Q, K, V
- 对于输入序列中的每一个词嵌入向量,都通过乘以 , , 矩阵生成对应的 Q, K, V 向量。
- 计算注意力分数 (Score)
- 当前处理的词的 Q 向量与所有词的 K 向量进行点积,得到注意力分数。
- 归一化 (Normalization)
- 将分数转换成一个总和为 1 的概率分布
- 得到 注意力权重
- 使用缩放点积注意力的归一化公式:
- 说明:
- 除以 可以抑制内积值在维度较大时变得过大,避免 softmax 进入极端区间导致梯度消失。
- 是键 向量的维度
- scale dot attention
- softmax 在最后一维上归一化,得到对每个 query 的注意力权重分布。
- QKV 是从 信息学 借用的词语
- query
- 模型当前关注点
- 模型尝试理解的对象
- 用于探查输入序列中的其他部分,以确定应当给予它们多少注意力。
- key
- 每个输入都有一个关联的 key
- 用于匹配 query
- value
- 表示输入项的实际内容或表征。
- 当模型确定了哪些 key(也即输入中最与当前 query(当前关注项)相关的部分)时,就会取出相应的 value。
- query
- 除以 可以抑制内积值在维度较大时变得过大,避免 softmax 进入极端区间导致梯度消失。
- Causal Attention - Masked Attention - Decoder Masked Self-Attention
- 在自回归模型中,当前词只能看到之前的词。
- 在计算注意力分数时,确保每个词只能看到它之前的词(或当前词),以保持自回归特性。
- 通过在计算注意力分数时使用掩码(mask)来实现。
- Improving Language Understanding by Generative Pre-Training
- Encoder-Decoder Cross-Attention
import math
scores = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k) # [*, seq_q, seq_k]
weights = torch.softmax(scores, dim=-1) # 注意力权重
context = weights @ V # 加权求和得到上下文向量
#
keys = inputs @ W_key
values = inputs @ W_value
scores = query @ keys.T
d_k = keys.shape[-1]
# math.sqrt(d_k) = d_k ** 0.5
weights = torch.softmax(scores / d_k ** 2, dim=-1)
context = weights @ values
import torch.nn as nn
# Single-Head
class SelfAttention_v1(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.d_out = d_out
self.W_q = nn.Parameter(torch.randn(d_in, d_out))
self.W_k = nn.Parameter(torch.randn(d_in, d_out))
self.W_v = nn.Parameter(torch.randn(d_in, d_out))
def forward(self, x):
K = x @ self.W_k
Q = x @ self.W_q
V = x @ self.W_v
scores = (Q @ K.T)
weights = torch.softmax(scores/ math.sqrt(self.d_out), dim=-1)
context = weights @ V
return context
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out,qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_q = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_k = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_v = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
K = self.W_k(x)
Q = self.W_q(x)
V = self.W_v(x)
scores = Q @ K.T
weights = torch.softmax(scores/ K.shape[-1] ** 0.5, dim=-1)
context = weights @ V
return context
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_q = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_k = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_v = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(cotext_length, cotext_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
K = self.W_k(x)
Q = self.W_q(x)
V = self.W_v(x)
scores = Q @ K.transpose(1, 2)
# 使用遮罩防止看到未来位置(因果/自回归)
scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens] == 0, torch.float('-inf'))
weights = torch.softmax(scores / K.shape[-1] ** 0.5, dim=-1)
weights = self.dropout(weights)
context = weights @ V
return context
# Multi-Head
class MultiHeadAttention_stack(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList([CausalAttention(d_in, d_out, context_length, dropout, qkv_bias) for _ in range(num_heads)])
def forward(self, x):
head_outputs = [head(x) for head in self.heads]
context = torch.cat(head_outputs, dim=-1)
return context
# 单一矩阵计算 Multi-Head
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_q = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_k = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_v = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(cotext_length, cotext_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
K = self.W_k(x)
Q = self.W_q(x)
V = self.W_v(x)
K = K.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2) # [b, num_heads, num_tokens, head_dim]
Q = Q.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2) # [b, num_heads, num_tokens, head_dim]
V = V.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2) # [b, num_heads, num_tokens, head_dim]
scores = Q @ K.transpose(-2, -1) # [b, num_heads, num_tokens, num_tokens]
scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens] == 0, -torch.inf)
weights = torch.softmax(scores / K.shape[-1] ** 0.5, dim=-1)
weights = self.dropout(weights)
context = (weights @ V).transpose(1, 2) # [b, num_tokens, num_heads, head_dim]
context = context.contiguous().view(b, num_tokens, self.d_out)
context = self.out_proj(context) # optional projection
return context
- 加权求和 (Weighted Sum)
softmax
给定一个实数向量 ,softmax 函数将其转换为另一个向量 ,其中每个 的计算公式为:
- 用途
- 将任意实数向量转换为概率分布
- 机器学习中常用于分类任务的输出层
import torch
# 代码表示
def softmax_naive(x):
return torch.exp(x) / torch.exp(x).sum(dim=0)
weights = torch.softmax(scores, dim=-1)
print("Sum of weights:", weights.sum()) # =1
采样
- 贪婪搜索 (Greedy Search):
- 方法:总是选择概率最高的那一个。
- 效果:确定性、无创造力、极其容易重复。基本不用于创意生成。
- Top-K 采样:
- 方法:在概率最高的 K 个选项中进行随机采样。
- 效果:排除了低概率的怪词,但候选池大小固定,不够智能。
- Top-P (Nucleus) 采样:
- 方法:在累积概率超过 P 的最小核心词汇集合中进行随机采样。
- 效果:目前最主流、最平衡的方法。候选池大小自适应,既能保证连贯性又能提供多样性。
- 温度采样 (Temperature):
- 方法:它不是一个独立的采样方法,而是一个调节器。通过调整温度值,来改变原始概率分布的“形状”,从而控制 Top-K 或 Top-P 采样的随机性程度。
- repetition_penalty - 重复惩罚 - 乘法/除法
- 降低那些在上下文中已经出现过的词再次出现的概率
- 用一个大于1的数除以重复词的 logit 分数
- 一个参数控制所有重复
- frequency_penalty / presence_penalty - 加法/减法
- 从重复词的 logit 分数中减去一个惩罚值
- frequency_penalty - 与词出现的次数有关
- presence_penalty - 只要出现过一次就惩罚
- next token logits
- 一维向量
- 向量的长度等于模型词汇表的大小 (Vocabulary Size)
- 向量每个元素的值:每个元素都是一个原始的、未经归一化的实数分数(logit),分别对应词汇表中的每一个token。分数越高,代表模型认为这个token是下一个词的可能性越大。
- 常用 Top-P 采样 + Temperature 的组合,这能在“准确性”和“创造性”之间达到最佳的、可控的平衡。
- 并行/推测解码 (Parallel / Speculative Decoding)
- 集束搜索 (Beam Search)
- 跟踪多个路径
BPE
- BPE (Byte Pair Encoding)
- 一种用于文本编码的算法
- 通过迭代地合并最常见的字节对来构建词汇表
- 生成的词汇表包含了常用词和子词单元,能够有效处理未登录词(OOV)
- 主要用于自然语言处理任务中的文本预处理
- 参考
- A New Algorithm for Data Compression
- 1994, Philip Gage
- byte pair 算法
- 数据压缩
- Neural Machine Translation of Rare Words with Subword Units
- 2015, 爱丁堡大学(University of Edinburgh) NLP
- BPE 分词
- A New Algorithm for Data Compression
GPT-2
一般研究学习会选择 GPT-2 作为入门模型,因为它是开源的,且具有较小的模型版本(如 124M、355M、774M、1558M),适合在个人电脑上进行实验。
caution
- 英文语料训练 WebText
- 中文 GPT-2 https://huggingface.co/uer/gpt2-chinese-cluecorpussmall
- Language Models are Unsupervised Multitask Learners
- 2019-02, OpenAI
- 提出 GPT-2
- 证明了通过扩大模型规模和数据量,模型无需微调就能展现出惊人的 零样本(Zero-Shot)多任务处理能力。
- 参考
| model | vocab | context length | embeddings | heads | layers | drop rate |
|---|---|---|---|---|---|---|
| GPT-2 117M | 50,257 | 1024 | 768 | 12 | 12 | 0.1 |
| GPT-2 345M | 1024 | 1024 | 24 | 24 | ||
| GPT-2 762M | 1024 | 1280 | 36 | 36 | ||
| GPT-2 1542M | 1024 | 1600 | 48 | 48 |
GPT-3
GPT-3 是闭源的,GPT-2 是开源的,因为 GPT-3 和 GPT-2 的架构和原理基本相同,所以可以先学习 GPT-2 的原理和代码实现,然后再了解 GPT-3 的细节。
- Language Models are Few-Shot Learners
- 2020-05, OpenAI
- 提出 GPT-3
- 展示了巨大模型规模下惊人的 上下文学习(In-Context Learning) 和 少样本(Few-Shot) 能力,用户无需微调,仅通过提供几个示例就能让模型完成任务。
- GPT-3 175B
- Q 12,288x128
- K 12,288x128
- V 12,288x128
- 96 heads
- 96 layers
- 12 layers
- 128 dim per head
- 175B params
- 12288 d_model
- Batch size 3.2M tokens
- 0.6 × 106 LR
- 与 GPT-2 相同的模型和架构
- FT, Few-Shot, Zero-Shot, One-Shot
Instruct Fine-Tuning
- https://arxiv.org/abs/2203.02155
- Training language models to follow instructions with human feedback
- InstructGPT
- SFT
- Reward Modeling
- RLHF
- “文本补全” -> “智能助手”